
Apache Hive 用户定义加解密函数(UDFs)
编辑最近遇到一个需求,要在数据湖中根据特定条件提取数据,同时需要保护数据不被其他人员直接查看。由于数据湖不允许部署自定义程序,因此我开始研究在Hive中编写自定义函数(UDF)来解决这个问题。接下来,我将记录编写自定义函数的过程。
什么是 Hive UDFs?
Hive 用户定义函数(UDFs)是用 Java 编写的自定义函数,可以集成到 Apache Hive 中。UDFs 接受参数、执行操作并返回结果。返回值可以是标量行或结果集,取决于 UDF 的代码和接口。UDFs 增强了传统 SQL 的功能。
Hive UDFs 的三种类型
标量函数(UDF):接受一行输入并返回标量值。例如,
length(string_col)返回字符串长度。聚合函数(UDAF):接受多行输入并返回单行输出。常见聚合函数包括
count、sum、avg、min、max等。表生成函数(UDTF):将单行输入转换为多行输出。例如,explode(ARRAY<T> a) 将数组元素转换为行。
内置 UDFs
常用的内置UDF包括 count(*) 和 length(string A)等,更多信息查看:Apache Hive : Hive UDFs
UDF 的工作原理
当 Hive 执行查询时,遇到 UDF 调用会执行以下步骤:
加载 UDF 类:Hive 从 JAR 包中加载用户定义的 UDF 类。
调用 evaluate 方法:根据 SQL 查询中的输入参数,调用 UDF 的 evaluate 方法。
返回结果:将 evaluate 方法的返回值作为查询结果的一部分。
编写自定义 UDFs
在国产化浪潮下,我结合了国产密码算法SM2和SM4,自定义了加解密函数。在撰写本文时,我使用的是 Hive 版本 4.0.0。
创建Maven项目
使用 JDK 8 版本,并引入与 Hive 对应版本的 hive-exec 依赖。需要注意将该依赖的 scope 设置为 provided,以确保在部署到 Hive 环境时不会包含 hive-exec 相关依赖,因为 Hive 运行环境中已经包含了这些依赖。以下是 pom.xml 文件:
<project>
<dependencies>
<!-- 其他依赖 -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version><!-- Hive对应版本号 --></version>
<scope>provided</scope>
</dependency>
<!-- 其他依赖 -->
</dependencies>
</project>
解密UDF
普通的UDF接收一个参数输出一个结果,我们只需要将自己UDF类继承 org.apache.hadoop.hive.ql.exec.UDF 即可,并实现自己的 evaluate 方法,这里注意 evaluate 方法并不是继承来的,而是 Hive UDF 的一种固定写法。
由于 Hive 支持多种输入和输出类型,evaluate 方法的参数和返回值类型可以灵活定义。例如:
public String evaluate(String input)
public int evaluate(int a, int b)
public boolean evaluate(boolean flag)
这种设计允许开发者根据业务需求自由扩展功能。
以下是我的解密类实现:
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.json.JSONObject;
import tech.timearrow.xxx.Constant;
import cn.hutool.core.util.ZipUtil;
import cn.hutool.crypto.SmUtil;
import cn.hutool.crypto.asymmetric.KeyType;
import cn.hutool.crypto.asymmetric.SM2;
import cn.hutool.crypto.symmetric.SM4;
import cn.hutool.core.codec.Base64;
import java.nio.charset.StandardCharsets;
/**
* <a href="https://hive.apache.org/docs/latest/hive-udfs_282102277/">Hive 官方文档</a>
* @author YahocenMiniPC
*/
@Description(name = "xxx_decrypt", value = "xxx_decrypt(string) - string", extended = "select xxx_decrypt(string) from table;")
public class DecryptResolver extends UDF {
public String evaluate(String input) throws HiveException {
//解析参数
JSONObject json = new JSONObject(input);
if (!json.has(Constant.CIPHERTEXT_KEY) || !json.has(Constant.SECRET_KEY)) {
throw new HiveException("参数结构错误。");
}
String ciphertext = json.getString(Constant.CIPHERTEXT_KEY);
String secretKey = json.getString(Constant.SECRET_KEY);
//使用 SM2 私钥解密 SM4 密钥
SM2 sm2 = SmUtil.sm2(Constant.SM2_PRIVATE_KEY, Constant.SM2_PUBLIC_KEY);
String sm4Key = sm2.decryptStr(secretKey, KeyType.PrivateKey);
//使用 SM4 密钥解密 ciphertext
SM4 sm4 = SmUtil.sm4(Base64.decode(sm4Key));
String gzipData = sm4.decryptStr(ciphertext);
//解压缩数据
byte[] compressedData = Base64.decode(gzipData);
byte[] originalData = ZipUtil.unGzip(compressedData);
return new String(originalData, StandardCharsets.UTF_8);
}
}优化
使用继承 GenericUDF 类,优化资源初始化过程。确保 initialize 方法只在第一次调用时执行,而 evaluate 方法会根据行数调用多次。
import cn.hutool.core.util.ObjUtil;
import cn.hutool.core.util.StrUtil;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import org.json.JSONException;
import org.json.JSONObject;
import cn.hutool.core.util.ZipUtil;
import cn.hutool.crypto.SmUtil;
import cn.hutool.crypto.asymmetric.KeyType;
import cn.hutool.crypto.asymmetric.SM2;
import cn.hutool.crypto.symmetric.SM4;
import cn.hutool.core.codec.Base64;
import java.nio.charset.StandardCharsets;
/**
* <a href="https://hive.apache.org/docs/latest/hive-udfs_282102277/">Hive 官方文档</a>
* @author YahocenMiniPC
* @deprecated CREATE TEMPORARY FUNCTION xxx_decrypt AS 'tech.timearrow.xxx.DecryptResolver' USING JAR '.../XxxEnDeUdf-1.0-SNAPSHOT-jar-with-dependencies.jar';
*/
@Description(name = "xxx_decrypt", value = "_FUNC(string) - string", extended = "select xxx_decrypt(string) from table;")
@Deprecated
public class DecryptResolver extends GenericUDF {
private static final long serialVersionUID = 1L;
private StringObjectInspector inputInspector;
private SM2 sm2;
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 1) {
throw new UDFArgumentException("函数 xxx_decrypt 只接受一个参数。");
}
inputInspector = (StringObjectInspector) arguments[0];
sm2 = SmUtil.sm2(Constant.SM2_PRIVATE_KEY, Constant.SM2_PUBLIC_KEY);
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
if (ObjUtil.isNull(arguments) || arguments.length != 1) {
throw new XxxError("函数 xxx_decrypt 只需要一个参数。");
}
String input = inputInspector.getPrimitiveJavaObject(arguments[0].get());
//校验参数不能为空且为json格式
if (StrUtil.isBlank(input)) {
throw new XxxError("参数错误。");
}
return decrypt(input);
}
@Override
public String getDisplayString(String[] children) {
return "xxx_decrypt(" + children[0] + ")";
}
public String decrypt(String input) throws XxxError {
try {
JSONObject json = new JSONObject(input);
if (!json.has(Constant.CIPHERTEXT_KEY) || !json.has(Constant.SECRET_KEY)) {
throw new XxxError("参数结构错误。");
}
String ciphertext = json.getString(Constant.CIPHERTEXT_KEY);
String secretKey = json.getString(Constant.SECRET_KEY);
// 使用 SM2 私钥解密 SM4 密钥
String sm4Key = sm2.decryptStr(secretKey, KeyType.PrivateKey);
// 使用 SM4 密钥解密 ciphertext
String gzipData = SmUtil.sm4(Base64.decode(sm4Key)).decryptStr(ciphertext);
// 解压缩数据
byte[] compressedData = Base64.decode(gzipData);
byte[] originalData = ZipUtil.unGzip(compressedData);
return new String(originalData, StandardCharsets.UTF_8);
} catch (JSONException e) {
throw new XxxError("参数错误。", e);
}
}
}加密UDAF
需要关注两个类:
AbstractGenericUDAFResolver是 Hive 中用于定义用户自定义聚合函数(UDAF)的核心类之一。它的主要作用是解析和验证 UDAF 的参数,并返回一个具体的GenericUDAFEvaluator实例来执行实际的聚合逻辑。GenericUDAFEvaluator是 Hive 中实现 UDAF 核心逻辑的关键类。它定义了 UDAF 的生命周期方法,包括初始化、迭代处理、部分结果生成、合并中间结果以及最终结果输出。init:初始化阶段,设置输入参数的类型检查器(ObjectInspector),并返回结果的类型检查器。
getNewAggregationBuffer:创建一个新的聚合缓冲区对象,用于存储中间状态。
reset:重置聚合缓冲区,清空中间状态。
iterate:处理单条输入数据,将其加入聚合缓冲区。
terminatePartial:生成部分聚合结果,通常用于分布式计算中的中间结果传输。
merge:合并多个部分聚合结果到当前聚合缓冲区。
terminate:生成最终的聚合结果。
以下是我的加密类实现:
import cn.hutool.core.codec.Base64;
import cn.hutool.core.util.ZipUtil;
import cn.hutool.crypto.SmUtil;
import cn.hutool.crypto.asymmetric.KeyType;
import cn.hutool.crypto.asymmetric.SM2;
import cn.hutool.crypto.symmetric.SM4;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.*;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.Text;
import java.io.Serializable;
import java.nio.charset.StandardCharsets;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import org.json.JSONObject;
import tech.timearrow.xxx.Constant;
/**
* <a href="https://hive.apache.org/docs/latest/hive-udfs_282102277/">Hive 官方文档</a>
* @author YahocenMiniPC
*/
@Description(name = "xxx_encrypt", value = "_FUNC(string...) - string", extended = "select xxx_encrypt(string...) from table;")
public class EncryptResolver extends AbstractGenericUDAFResolver {
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {
// 参数数量校验
if (info.getParameterObjectInspectors().length < 1) {
throw new UDFArgumentTypeException(0, "至少需要一个参数输入");
}
// 返回自定义Evaluator
return new EncryptEvaluator();
}
@Override
@Deprecated
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) {
throw new UnsupportedOperationException("请使用新版参数校验接口");
}
static class EncryptEvaluator extends GenericUDAFEvaluator {
private PrimitiveObjectInspector[] inputs;
private final Text result = new Text();
/**
* 初始化阶段
*/
@Override
public ObjectInspector init(Mode mode, ObjectInspector[] parameters) throws HiveException {
super.init(mode, parameters);
inputs = new PrimitiveObjectInspector[parameters.length];
for (int i = 0; i < parameters.length; i++) {
inputs[i] = (PrimitiveObjectInspector) parameters[i];
}
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
/**
* 获取一个新的聚合对象。
*/
@Override
public EncryptBuffer getNewAggregationBuffer() {
return new EncryptBuffer();
}
/**
* 重置聚合对象
*/
@Override
public void reset(AggregationBuffer agg) {
((EncryptBuffer) agg).encryptedChunks.clear();
}
/**
* 处理单条数据
*/
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
if (parameters == null || parameters.length == 0) {
return;
}
// 构建JSON对象
JSONObject json = new JSONObject();
for (int i = 0; i < parameters.length; i++) {
if (parameters[i] != null) {
String key = "param" + (i + 1);
Object val = inputs[i].getPrimitiveJavaObject(parameters[i]);
json.put(key, val);
}
}
((EncryptBuffer) agg).add(json.toString());
}
/**
* 返回部分聚合结果
*/
@Override
public Text terminatePartial(AggregationBuffer agg) {
EncryptBuffer buffer = (EncryptBuffer) agg;
// 将聚合结果转换为 Text 对象
StringBuilder sb = new StringBuilder();
for (String chunk : buffer.getEncryptedChunks()) {
sb.append(chunk).append("|");
}
if (sb.length() > 0) {
sb.setLength(sb.length() - 1); // 去掉最后一个分隔符
}
Text result = new Text();
result.set(sb.toString());
return result;
}
/**
* 合并中间结果
*/
@Override
public void merge(AggregationBuffer agg, Object partial) {
if (partial == null) {
return;
}
Text partialText = (Text) partial;
String[] chunks = partialText.toString().split("\\|");
for (String chunk : chunks) {
((EncryptBuffer) agg).add(chunk);
}
}
/**
* 生成最终输出
*/
@Override
public Text terminate(AggregationBuffer agg) throws HiveException {
List<String> chunks = ((EncryptBuffer) agg).getEncryptedChunks();
// 使用 StringBuilder 优化字符串拼接
StringBuilder merged = new StringBuilder(chunks.size() * 50); // 假设平均长度为50
for (int i = 0; i < chunks.size(); i++) {
merged.append(chunks.get(i));
if (i < chunks.size() - 1) {
merged.append("|");
}
}
// 统一加密
try {
result.set(encrypt(merged.toString()));
} catch (Exception e) {
throw new HiveException("加密失败: " + e.getMessage(), e);
}
return result;
}
}
static class EncryptBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer implements Serializable {
/**
* 存储加密后的数据块(线程安全容器)
*/
private final CopyOnWriteArrayList<String> encryptedChunks = new CopyOnWriteArrayList<>();
/**
* 添加单条加密数据
* @param encryptedData 加密后的数据
*/
public void add(String encryptedData) {
encryptedChunks.add(encryptedData);
}
/**
* 获取当前所有加密块(用于最终输出)
* @return List<String>
*/
public List<String> getEncryptedChunks() {
// 返回不可变列表以保证数据不可变性
return Collections.unmodifiableList(encryptedChunks);
}
}
public static String encrypt(String input) throws HiveException {
try {
// 1. 压缩原文
byte[] compressedData = ZipUtil.gzip(input.getBytes(StandardCharsets.UTF_8));
String gzipData = Base64.encode(compressedData);
// 2. 生成 SM4 密钥
SM4 sm4 = SmUtil.sm4();
byte[] sm4KeyBytes = sm4.getSecretKey().getEncoded();
String sm4Key = Base64.encode(sm4KeyBytes);
// 3. 使用 SM4 加密压缩后的数据
String ciphertext = sm4.encryptHex(gzipData);
// 4. 使用 SM2 加密 SM4 密钥
SM2 sm2 = SmUtil.sm2(Constant.SM2_PRIVATE_KEY, Constant.SM2_PUBLIC_KEY);
String secretKey = sm2.encryptHex(sm4Key, KeyType.PublicKey);
// 5. 组装加密后结果
JSONObject cipher = new JSONObject();
cipher.put(Constant.CIPHERTEXT_KEY, ciphertext);
cipher.put(Constant.SECRET_KEY, secretKey);
return cipher.toString();
} catch (Exception e) {
throw new HiveException("加密失败: " + e.getMessage(), e);
}
}
}测试自定义函数
我这里使用docker官方提供hive镜像测试我的自定义函数
启动容器并进入容器内部:
docker stop hive4 && docker rm hive4 && docker run -d -p 10000:10000 -p 10002:10002 -v /data/hive:/opt/hive/mydata --env SERVICE_NAME=hiveserver2 --name hive4 apache/hive:4.0.0 && docker exec -it hive4 /bin/bash使用容器自带的 beeline 登录 hive:
beeline -u jdbc:hive2://localhost:10000加载自定义函数
在这里,使用 CREATE TEMPORARY FUNCTION 创建临时函数,该函数仅在当前 beeline 会话中有效。如果需要创建永久函数,则应删除 TEMPORARY 关键字。我们选择创建临时函数进行测试,以便方便进行反复调试。
-- 加密函数
CREATE TEMPORARY FUNCTION xxx_encrypt AS 'xxx.encrypt.EncryptResolver' USING JAR '/opt/hive/mydata/XxxEnDeUdf-1.0-SNAPSHOT-jar-with-dependencies.jar';
-- 解密函数
CREATE TEMPORARY FUNCTION xxx_decrypt AS 'xxx.decrypt.DecryptResolver' USING JAR '/opt/hive/mydata/XxxEnDeUdf-1.0-SNAPSHOT-jar-with-dependencies.jar';验证是否加载成功
执行 SQL 查询 SHOW FUNCTIONS;,如果在列表中出现我们的函数名,就表示加载成功了。
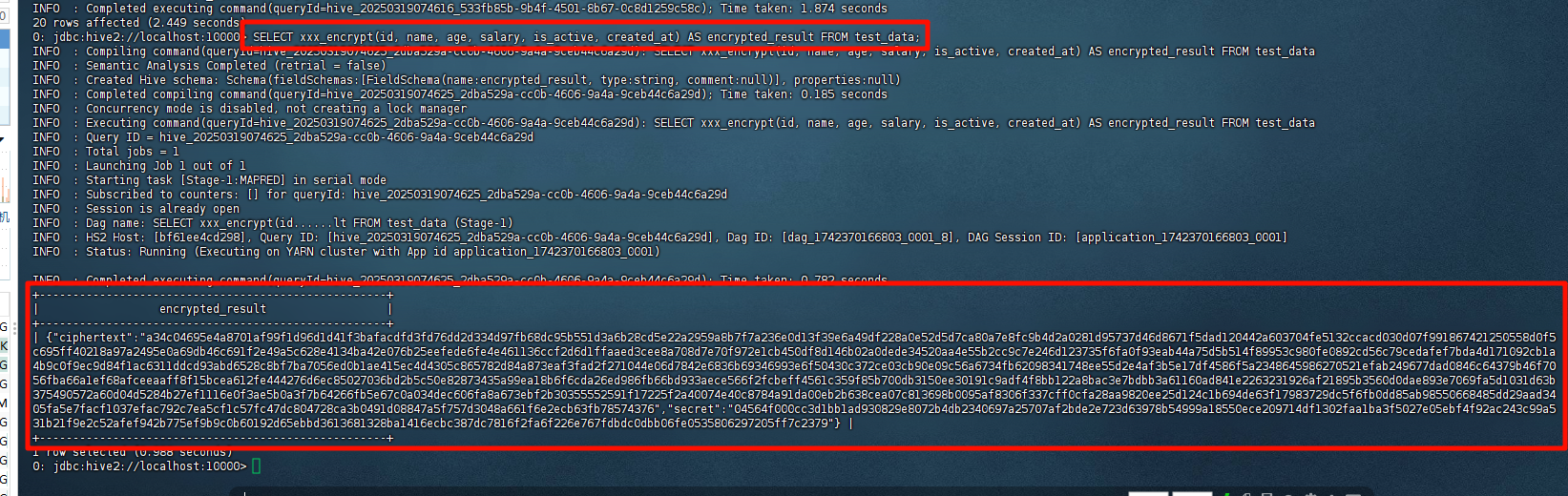
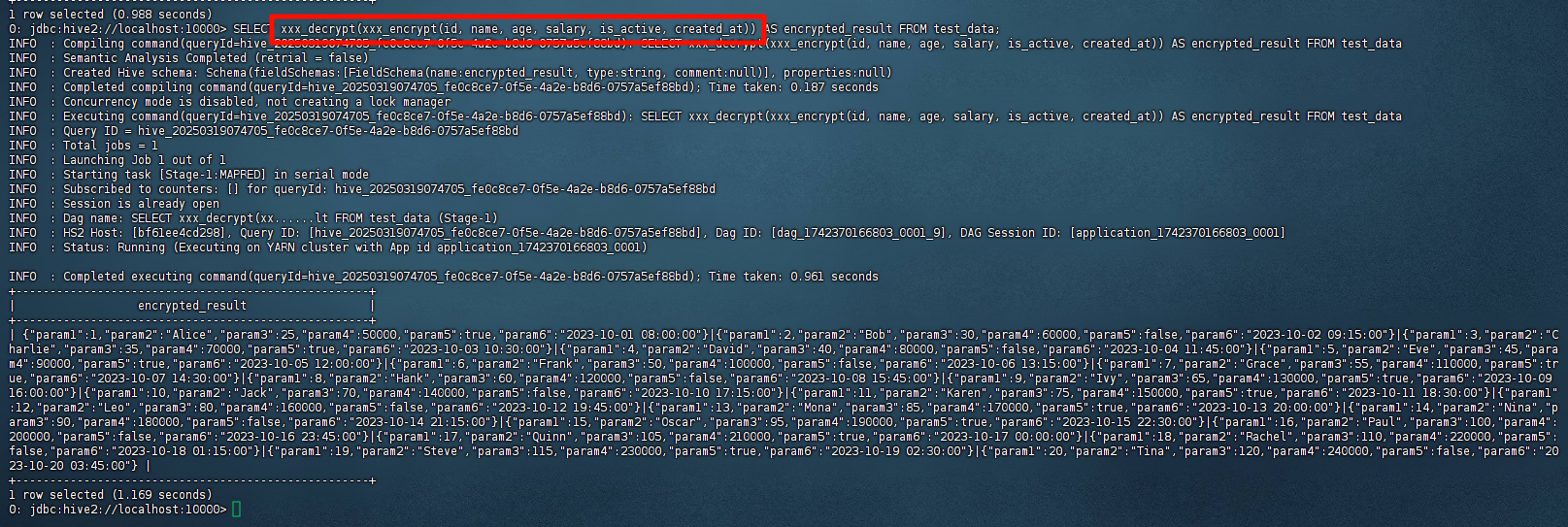
使用加解密函数
直接上图,看结果
- 0
- 0
-
赞助
 支付宝
支付宝
 微信
微信
-
分享